Inteligência Artificial
Reconhecimento de Padrões com Rede Neural
Você está em: MarMSX >> Cursos >> AI
Neste capítulo extra, vamos por em prática o que aprendemos nos capítulos anteriores sobre redes neurais artificiais.
A proposta aqui é utilizar uma grade de 8x8 pontos como entrada de uma rede neural, para que sejam detectados padrões de números entre 0 e 9.
Detecção de Padrões em Imagens
Muitas aplicações hoje em dia utilizam redes neurais artificiais para a detecção de objetos em uma cena. Entretanto, as redes utilizadas para este fim são uma sofisticação da rede neural básica. Estamos falando das CNNs, ou seja, uma Rede Neural Convolucional [1].
Na nossa experiência, vamos aprender o conceito básico sobre a utilização de redes neurais tradicionais na detecção de padrões em imagens, suas vantagens e desvantagens.
Para aprender mais sobre as CNNs, sugerimos a leitura do livro [1].
Configuração da rede neural
A experiência utilizará uma grade de 8x8 pontos, que é a mesma utilizada pela tabela ASCII do MSX para desenhar os caracteres.

Cada ponto da grade servirá de entrada para a rede neural, que possui a seguinte configuração:
Entradas: 64
Camada escondida:
Número de neurônios: 15 / 30
Função de ativação: tansig
Saída:
Número de neurônios: 10
Função de ativação: linear
A relação entre os pontos da grade e as entradas da rede neural é apresentada a seguir.
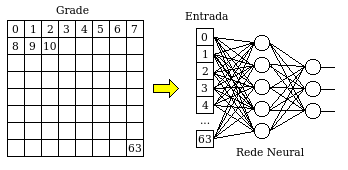
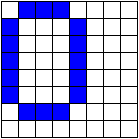
Os desenhos dos caracteres de 0 a 9 são baseados nos caracteres do MSX, no qual são apresentados na figura a seguir.

Onde os pixels acesos correspondem ao valor 1, enquanto que os apagados correspondem a 0.
Por exemplo, o desenho do número 0 produz o seguinte vetor de entrada:
E = { 0,1,1,1,0,0,0,0,
1,0,0,0,1,0,0,0,
1,0,0,1,1,0,0,0,
1,0,1,0,1,0,0,0,
1,1,0,0,1,0,0,0,
1,0,0,0,1,0,0,0,
0,1,1,1,0,0,0,0,
0,0,0,0,0,0,0,0 }
Treinamento da rede
Por se tratar de uma rede neural complexa, sugerimos a utilização de um programa de um pacote de redes neurais para PC. No nosso caso, utilizamos o pacote nnet do Octave. O Octave é uma versão em software livre para Windows e Linux do Matlab.
Nós já realizamos o treinamento e disponibilizamos os valores dos pesos e bias para rodar no MSX. Entretanto, caso deseje realizar o treinamento por conta própria, descreveremos a seguir o processo a ser realizado no Octave.
A matriz P, com 64 linhas e 10 colunas, contém as 10 entradas correspondentes aos caracteres de 0 a 9, onde cada coluna corresponde a uma entrada.
A matriz T, com 10 linhas e 10 colunas, contém as 10 saídas correspondentes aos caracteres de 0 a 9, onde cada coluna corresponde a uma saída.
Padrões de saída adotados:
1 - { 1,0,0,0,0,0,0,0,0,0 }
2 - { 0,1,0,0,0,0,0,0,0,0 }
3 - { 0,0,1,0,0,0,0,0,0,0 }
4 - { 0,0,0,1,0,0,0,0,0,0 }
5 - { 0,0,0,0,1,0,0,0,0,0 }
6 - { 0,0,0,0,0,1,0,0,0,0 }
7 - { 0,0,0,0,0,0,1,0,0,0 }
8 - { 0,0,0,0,0,0,0,1,0,0 }
9 - { 0,0,0,0,0,0,0,0,1,0 }
0 - { 0,0,0,0,0,0,0,0,0,1 }
Script:
% Cria rede
Pr = repmat([0 1], [64 1]);
Ss = [15 10];
trf = {'tansig', 'purelin'};
net = newff(Pr, Ss, trf);
% Treina
net = train(net, P, T);
% Salva
save('net.dat', 'net');
Após salvar o arquivo "net.dat", podemos abri-lo em um editor de textos. A variável IW contém os pesos da primeira camada, LW os pesos da segunda camada e b os valores do bias.
Baixe aqui um pacote com os arquivos para Matlab/Octave.
O detector de padrões em Basic
Vamos juntar dois programas em um só: o editor de caracteres utilizado no capítulo de Reconhecimento de Padrões e a rede neural do capítulo de Redes Neurais - Feed Forward.

Para rodar as experiências a seguir, utilize os programas contidos no pacote rn_pad_num.zip.
Nota importante: inicie o MSX segurando o CONTROL, pois as experiências 2 e 3 consomem muita memória.
Experiência 1
1 desenho para cada caractere.
15 neurônios na camada escondida.
Na primeira experiência, utilize os seguintes arquivos do pacote:
RN_NUM.BAS - Arquivo em Basic com o aplicativo.
NET_NUM.DAT - Dados dos pesos e bias obtidos no Octave.
Atividades sugeridas:
- Desenhe os números EXATAMENTE como no gabarito mostrado na seção Configuração da rede neural.
- Agora, desenhe um número qualquer, modificando APENAS UM ponto.
- Depois, desenhe uma nova forma para um número, como por exemplo:
- Por fim, desenhe qualquer número exatamente como o gabarito, mas:
- Deslocando o número horizontalmente ou verticalmente.
- Rotacionando o número.
Na primeira experiência, a rede foi capaz de acertar os números. Ao modificarmos um pixel, a rede erra na previsão. O mesmo ocorre ao gerarmos novos desenhos para os números, ou quando deslocamos o número de sua posição original.
O problema do erro ao modificarmos um pixel indica que o número de neurônios na camada escondida é insuficiente.
Experiência 2
1 desenho para cada caractere.
30 neurônios na camada escondida.
Na segunda experiência, utilize os seguintes arquivos do pacote:
RN_NUM2.BAS - Arquivo em Basic com o aplicativo.
NET_NUM2.DAT - Dados dos pesos e bias obtidos no Octave.
Repita os procedimentos da experiência anterior.
Ao desenharmos exatamente um número, a rede acerta. Ao modificarmos um pixel, a rede também acerta na previsão. Entretanto, quando fazemos novos desenhos para os números, a previsão é errada. Além disso, a rede continua errando quando um número é deslocado.
Quanto ao problema de novas formas, devemos utilizar mais padrões no treinamento para cada caractere.
Experiência 3
3 desenhos para cada caractere.
30 neurônios na camada escondida.
Na terceira experiência, utilize os seguintes arquivos do pacote:
RN_NUM3.BAS - Arquivo em Basic com o aplicativo.
NET_NUM3.DAT - Dados dos pesos e bias obtidos no Octave.
Os três padrões para os números:
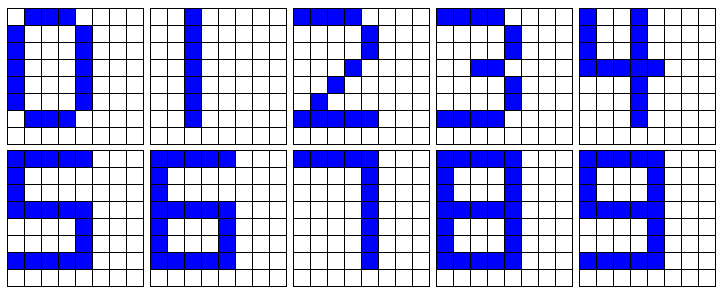

A rede agora se tornou mais robusta, pois aceita novas formas de caracteres, bem como a falha de alguns pontos. Entretanto, continua falhando quando o número é deslocado.
Nota: se tivéssemos utilizado 15 neurônios na camada escondida em vez de 30, a rede seria capaz de acertar as diferentes formas dos números, mas estes teriam que ser desenhados EXATAMENTE como os modelos.
Conclusões
A rede neural pôde reconhecer os números de 0 a 9, mas com algumas restrições.
Assim como vimos no capítulo de Reconhecimento de Padrões, devemos utilizar diversas formas do mesmo caractere para fazer com que o sistema de reconhecimento seja mais robusto.
No ajuste ao gabarito, o aumento da quantidade de formas de caracteres acarreta em mais uso de memória e mais tempo de processamento, uma vez que há mais comparações a serem feitas. Já na rede neural, o tamanho da rede é invariável quanto ao número de amostras de treinamento. Dessa forma, o treinamento utilizando mais formas de caracteres irá ser mais penoso. Porém, uma vez treinada a rede, o tempo gasto nas previsões será sempre o mesmo.
Referências
1. Aprendizado Profundo para Leigos, John Paul Mueller e Luca Massaron. Editora Alta Books, 2020.